Kubernetes

Kubernetes
吴阴天部署方式的进化
大学刚接触开发时,我们购入了一台学生服务器进行测试。前后端以及数据库同时部署在上面: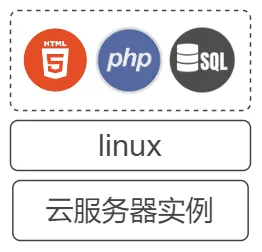
后来同时参加多个比赛,还要照顾学校里的课程,部署的应用就多了起来。虽然升级了配置,但某一个应用对系统的操作量过大时,总是会造成其它应用的访问阻塞。为了分配有限的计算机资源,我们开始使用虚拟机: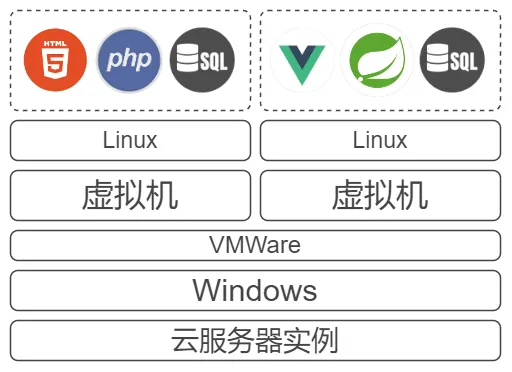
现在我家里有一个服务器,还租用了云服务商的服务器。将我已经成型的一些应用打包成容器并上传到自建的docker仓库中,这样就不需要再为每个服务手动配置环境,以及麻烦地上传各种文件了: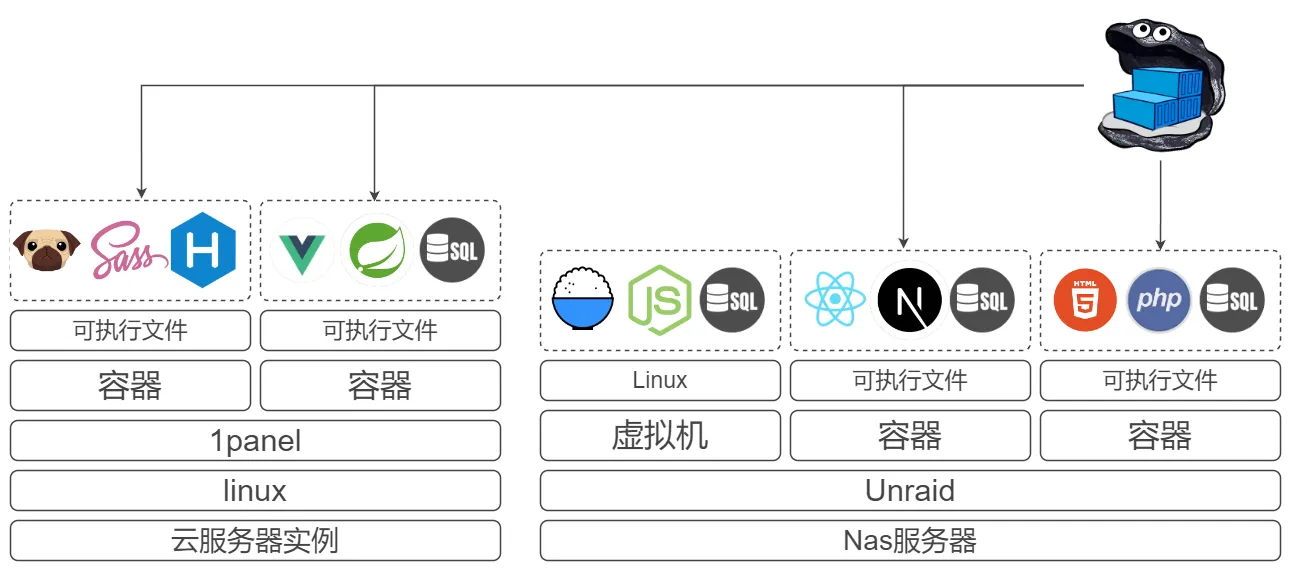
目前我的这套系统已经高可用了,它们都通过dockerfile中的CMD的命令拉取代码并重新构建,意味着重启docker即可更新。
但这都是在一切正常运行的情况下,当遇到一些极端情况还是需要麻烦的手动处理,譬如说:
- 云服务器资源较少,偶尔会挂掉。就要重启云服务器并对比应用的资源占用,考虑把它放回家里的大服务器。
- 但是家里的服务器需要定期进行奇偶校验,那时访问家中的服务就会比较慢,而且得持续若干天,这时就得有选择地把重要应用转移到云服务器上。
- 无法尽可能地利用和调配服务器资源,比如说某些应用吃得多,某些应用吃得少,总是会有浪费。
但是,没有什么问题是加一个中间件不能解决的。
k8s
中文官网
只需要一个yaml文件,定义应用部署的顺序,就能将应用部署到各个服务器上,让他们自动扩缩容,并且在服务器挂了之后,会自动在其他服务器上重新部署。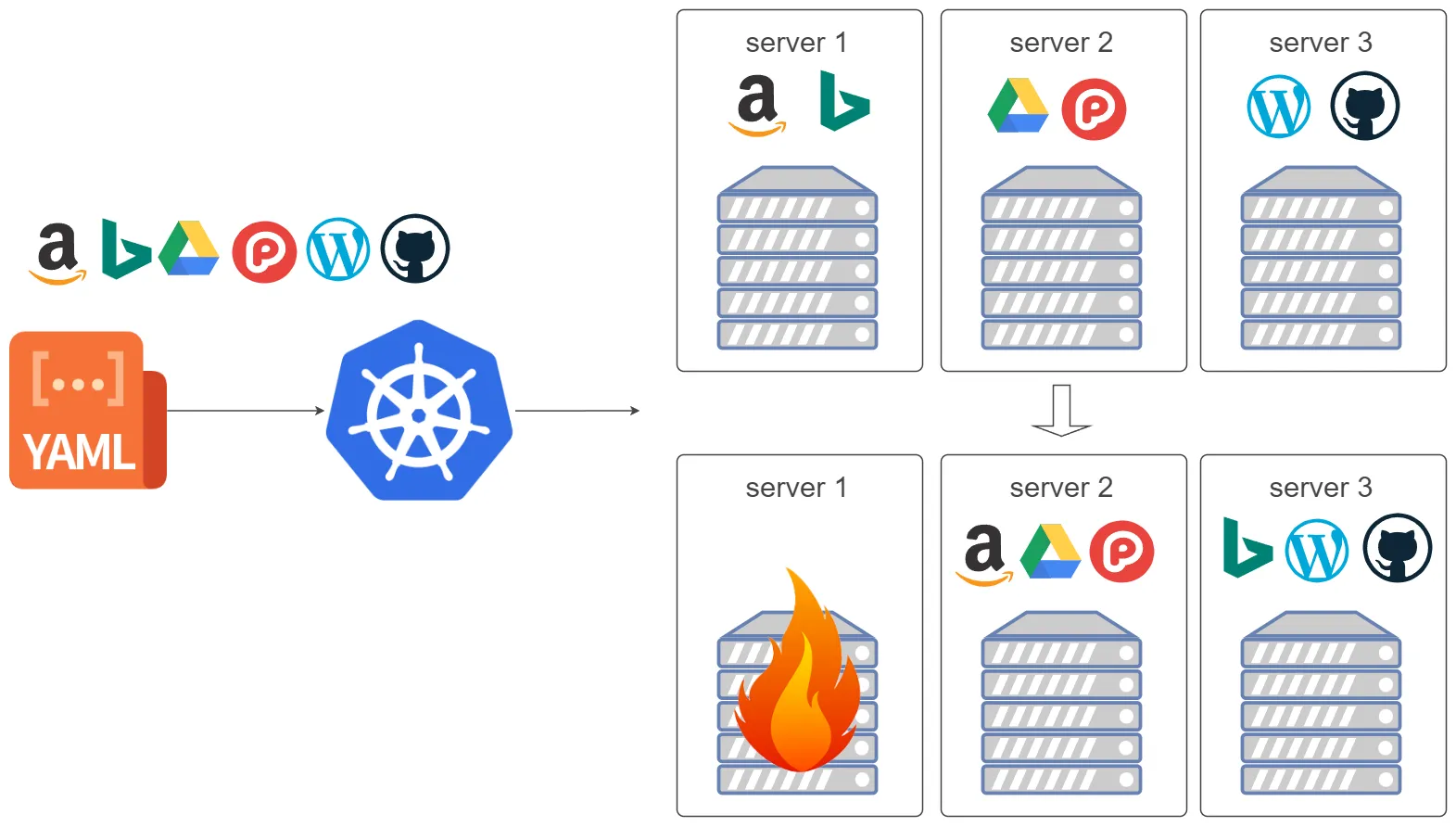
架构
k8s会将我们的服务器分为控制平面和Node两部分,其中控制平面负责控制和管理Node,而Node则用于实际运行各个应用服务。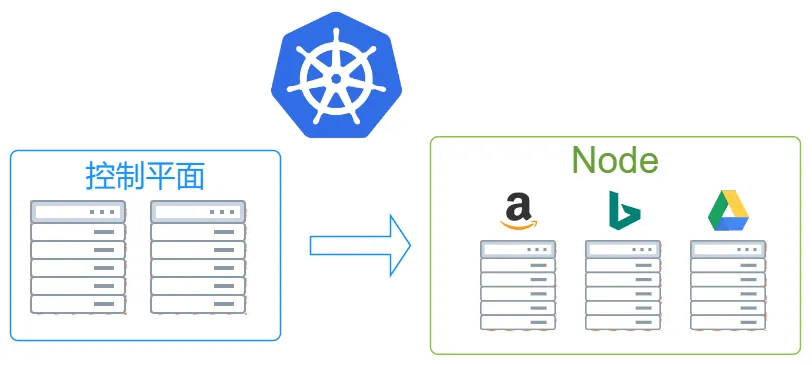
控制平面
过去我们需要登录到每台服务器去手动操作,现在则可以通过调用k8s提供的API来进行操作,这些API由控制平面中的API Server组件提供: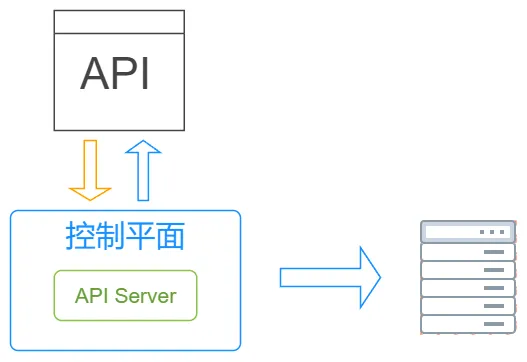
过去我们需要查看每台服务器剩余的内存和空间,来决定将服务部署到哪里,现在决策的部分交由Scheduler组件完成,而停止/创建操作则由Controller Manager来完成。这些动作会产生相应的数据,因此还有一个ETCD将数据保存至存储层。这就是控制平面内有的全部组件: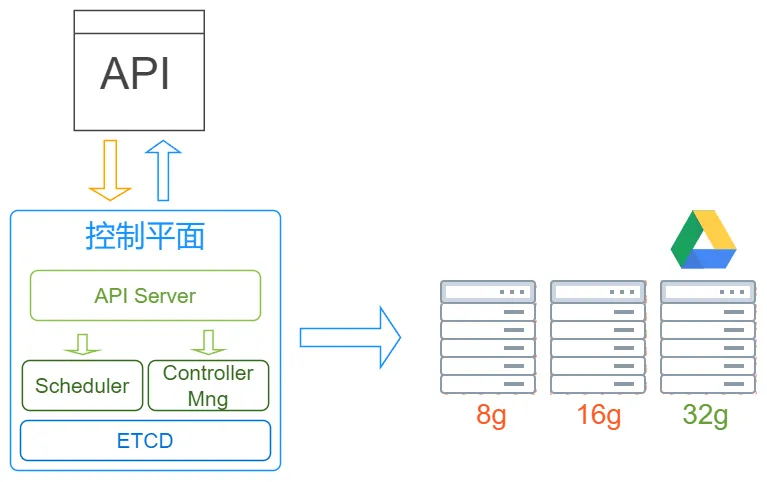
Node
Node是实际的工作节点,它可以是裸机服务器,也可以是虚拟机。一台Node上会同时运行多个应用服务,这些应用服务共享Node的内存和CPU等计算资源。
而在Node上部署应用服务,使用的是docker容器部署。每当我们部署一个应用容器,还需为它绑定一个日志容器和一个监控采集器容器,这三个容器的组合,称之为Pod。
一台Node上,可以同时运行多个Pod,而控制这些Pod运行的组件叫做Container Runtime。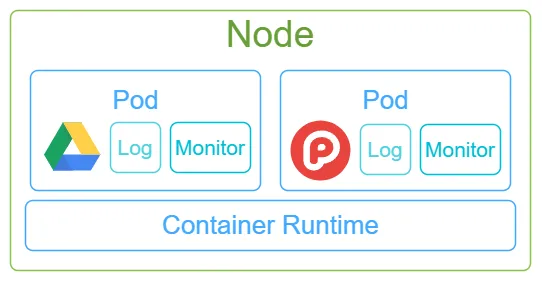
Pod是k8s中最小的调度单位,它们可以从一个Node上被调度到另一个Node上,以进行扩缩容的操作。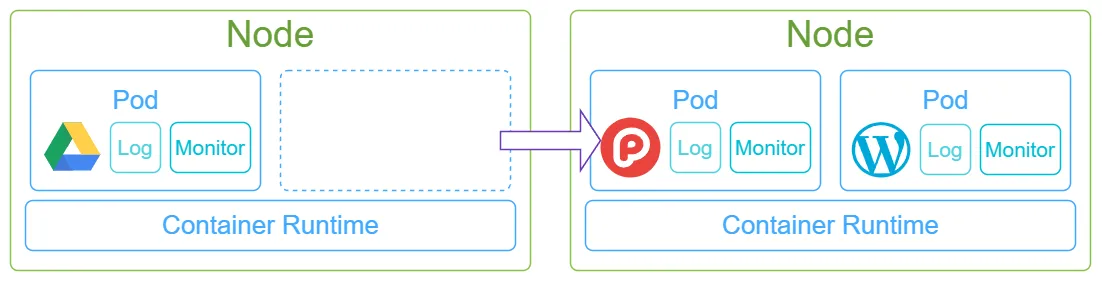 完成这些操作,需要使用到控制平面中的Controller Manager组件,而Node中接受其命令的组件叫做Kubelet。同时,Node中还有一个KubeProxy组件,通过该组件,外部的请求就能被转发到相应的pod中。
完成这些操作,需要使用到控制平面中的Controller Manager组件,而Node中接受其命令的组件叫做Kubelet。同时,Node中还有一个KubeProxy组件,通过该组件,外部的请求就能被转发到相应的pod中。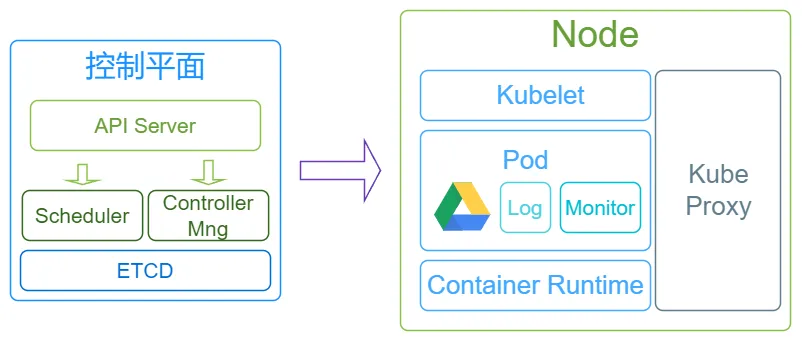
集群
一组控制平面和一组Node,就可以组成一个集群。通常我们可以有多个集群,比如说用于开发的集群和用于生产的集群。亦或者不同项目的不同集群组。
外部架构
为了使外部可以访问集群内部的服务,因此我们还需要一个入口控制器,比如Ingress控制器。
当我们发出请求时,请求会先经过ingress,再由ingress转发到容器内的Kube Proxy组件,Kube Proxy再转发到相应的Pod内。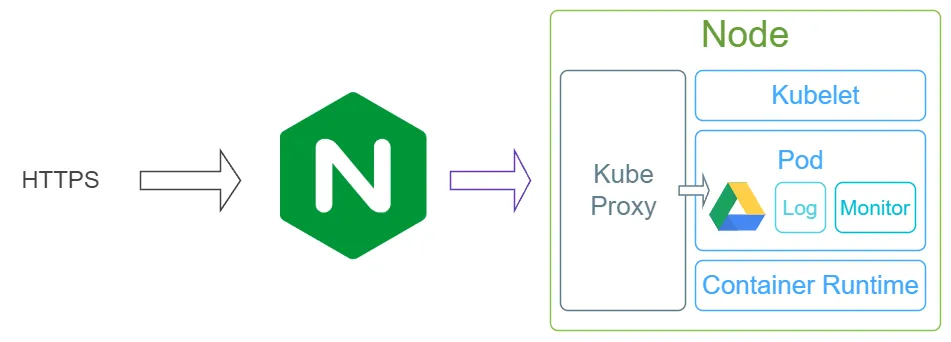
构建平台
kubernetes本身可以通过kubectl命令进行操作,但作为一个完整的工作流,我们可以借助k8s提供的API构建自己的平台,通过点击/选择完成这些相似、重复的事情。
譬如可以直接将k8s做进持续集成的平台中。